
📄 One paper accepted to ICML 2026
Our paper “Empirical Gaussian Processes” was accepted to ICML 2026.
PhD Computer Science
University of Sydney
BSc (Honours Class 1) Computer Science
University of New South Wales (UNSW) Sydney
My research is in probabilistic machine learning, with particular focus on approximate Bayesian inference and Gaussian processes, and their applications to Bayesian optimization. More broadly, my interests extend to automated machine learning (AutoML), encompassing hyperparameter optimization and adaptive resource allocation techniques such as early stopping and scaling laws. Past work includes graph representation learning and deep generative models. Some of this work has appeared as Orals and Spotlights at NeurIPS and ICML.
Always happy to hear from people working on related problems — get in touch.
Our paper “Empirical Gaussian Processes” was accepted to ICML 2026.
Our paper “Ax — A Platform for Adaptive Experimentation” was accepted to AutoML 2025 (ABCD Track).
Started as a Research Scientist at Meta on the Adaptive Experimentation team within Central Applied Science (CAS), based in New York City.
Submitted my PhD thesis, Probabilistic Machine Learning in the Age of Deep Learning, at the University of Sydney.
Our paper “Spherical Inducing Features for Orthogonally-Decoupled Gaussian Processes” was accepted to ICML2023 as an Oral Presentation!
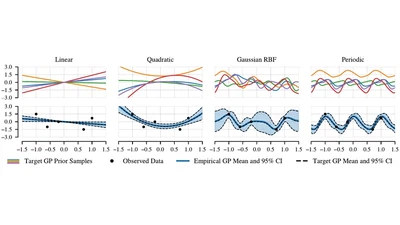
We study Empirical GPs, a principled framework for constructing flexible, data-driven Gaussian process priors. By estimating mean and covariance directly from a corpus of …

We present Ax, an open-source platform for adaptive experimentation built on BoTorch. Off the shelf, Ax achieves state-of-the-art performance across a wide range of synthetic and …
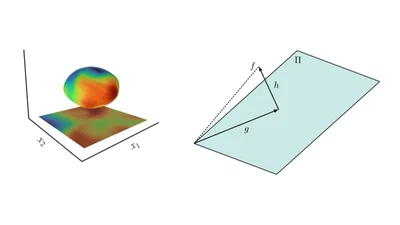
We introduce spherical inter-domain inducing features that yield more flexible, data-dependent basis functions for orthogonally-decoupled GP approximations, narrowing the …
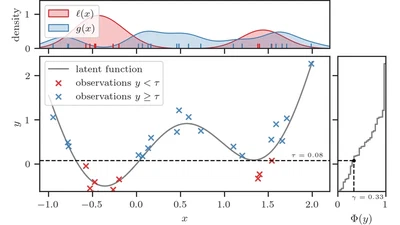
We reformulate the computation of the acquisition function in Bayesian optimization (BO) as a probabilistic classification problem, providing advantages in scalability, …
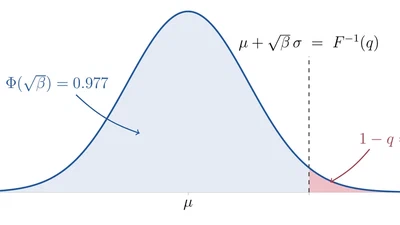
We show that UCB is a quantile of the predictive distribution in disguise, elicitable by the pinball loss even though no scalar loss can elicit the moment formula directly. The …

We analyze nine years of ICLR reviews and find that Reviewer 2 is not the problem.
We tour a chezmoi-templated dotfiles setup that bootstraps a fresh machine in one command — terminal, shell, prompt, multiplexer, multi-environment templating, and the developer …
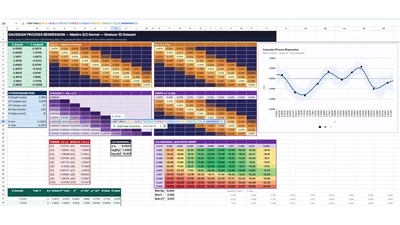
We implement a fully functional Gaussian Process regression pipeline — Cholesky decomposition, posterior predictions, and gradient-based hyperparameter optimization — in pure …
We give a short and practical guide to efficiently computing the Cholesky decomposition of matrices perturbed by low-rank updates.
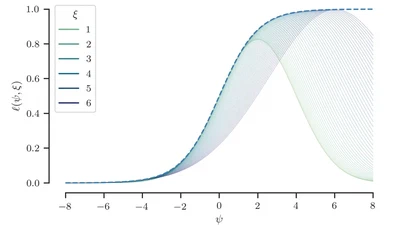
We swap Gibbs sampling for mean-field variational inference in the Pólya-Gamma augmented model and watch the classical Jaakkola-Jordan bound on the logistic sigmoid fall out, EM …
The 38th International Conference on Machine Learning (ICML 2021), virtual.
ELLIS AutoML Seminars (virtual).
NeurIPS 2020 4th Workshop on Meta-Learning (virtual).
Amazon Machine Learning Community Tech Talk, Berlin.
ICML 2018 Workshop on Theoretical Foundations and Applications of Deep Generative Models (TAGDM), Stockholm.

