Louis Tiao
Research Scientist
Meta - Central Applied Science (CAS) Team, NYC
Bio
Hi. I am Louis Tiao, a machine learning (ML) research scientist with a broad interest in probabilistic ML and a particular focus on approximate Bayesian inference and Gaussian processes, and their applications to Bayesian optimization and graph representation learning. I obtained my PhD from the University of Sydney, where I worked with Edwin Bonilla and Fabio Ramos. Our research has garnered recognition at premier conferences like NeurIPS and ICML, where our work has routinely been selected as Oral/Spotlight talks.
Starting in August, I will be joining Meta in New York City as a Research Scientist in the Adaptive Experimentation (AE) arm of the Central Applied Science (CAS) Team. In this role, I will continue to advance the frontiers of Bayesian optimization, Gaussian processes, and more broadly, sample-efficient decision-making and probabilistic modeling, with a focus on applications in automated machine learning (AutoML) and deep learning.
Before pursuing my doctorate, I obtained a BSc in Computer Science with First Class Honours from the University of New South Wales (UNSW Sydney), where I majored in artificial intelligence (AI) and minored in mathematics. I began my professional career in ML as a software engineer at National ICT Australia (NICTA), which later merged into CSIRO’s Data61—the AI research division of Australia’s national science agency.
During my PhD, I’ve had the privilege of collaborating with exceptional people through multiple rewarding industrial research internships. In the Summer and Fall of 2019, I completed a research internship at Amazon in Berlin, Germany, where I worked with Matthias Seeger, Cédric Archambeau, and Aaron Klein. Between Fall 2021 and Spring 2022, I worked with Vincent Dutordoir and Victor Picheny at Secondmind Labs in Cambridge, UK. More recently, in Summer 2022, I extended my stay in Cambridge and returned to Amazon, reuniting virtually with my former Berlin team.
Download my resumé .
- Probabilistic Machine Learning
- Approximate Bayesian Inference
- Gaussian Processes
- Bayesian Optimization
Ph.D. in Computer Science (Machine Learning), 2023
University of Sydney
B.Sc. (Honours Class 1) in Computer Science (Artificial Intelligence and Mathematics), 2015
University of New South Wales
News
Employment
Research Experience
As an applied scientist intern at Amazon Web Services (AWS), I led an explorative research project focused on addressing the challenges of hyperparameter optimization for large language models (LLMs). Our primary objective was to gain a comprehensive understanding of the scaling behavior of LLMs and investigate the feasibility of extrapolating optimal hyperparameters from smaller LLMs to their massive counterparts. This hands-on work involved orchestrating the parallel training of multiple LLMs from scratch across numerous GPU cloud instances to gain insights into their scaling dynamics.
During this internship, I was fortunate to be reunited with Aaron Klein, Matthias Seeger, and Cédric Archambeau, with whom I had previously collaborated during an earlier internship at AWS Berlin.
As a student researcher at Secondmind (formerly Prowler.io), a research-intensive AI startup renowned for its innovations in Bayesian optimization (BO) and Gaussian processes (GPs), I contributed impactful research and open-source code aligned with their focus on advancing probabilistic ML. Specifically, I developed open-source software to facilitate sampling efficiently from GPs, substantially improving their accessibility and functionality. Additionally, I led a research initiative to improve the integration of neural networks (NNs) with GP approximations, bridging a critical gap between probabilistic methods and deep learning. These efforts culminated in a research paper that was selected for an oral presentation at the International Conference on Machine Learning (ICML).
I had the privilege of collaborating closely with Vincent Dutordoir and Victor Picheny during this period.
As an applied scientist intern at Amazon Web Services (AWS), I contributed to the development of the Automatic Model Tuning functionality in AWS SageMaker. My primary focus was on advancing AutoML and hyperparameter optimization, particularly Bayesian optimization (BO) methods. I spearheaded a research project aimed at integrating multi-fidelity BO with asynchronous parallelism to significantly improve the efficiency and scalability of model tuning. This initiative led to the development of a research paper and the release of open-source code within the AutoGluon, subsequently forming the basis of the SyneTune library.
I had the privilege of working closely with Matthias Seeger, Cédric Archambeau, and Aaron Klein during this internship.
Select Publications

Recent Posts
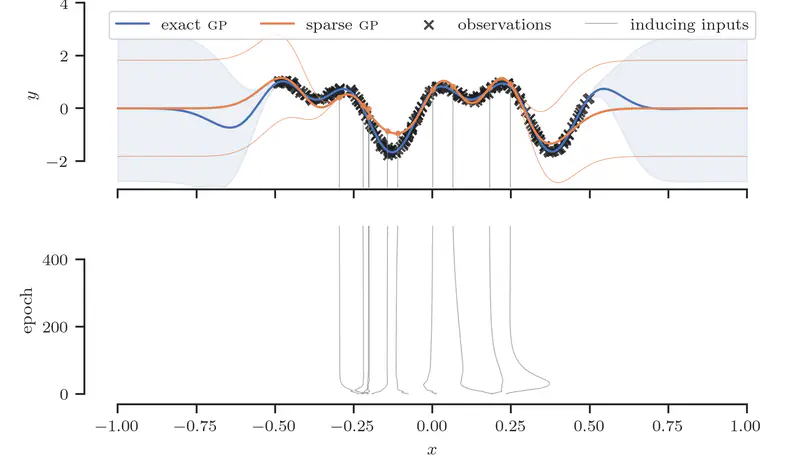
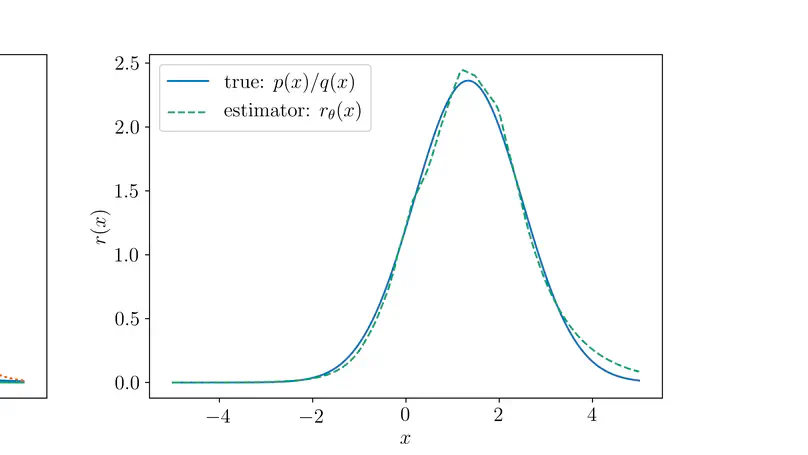

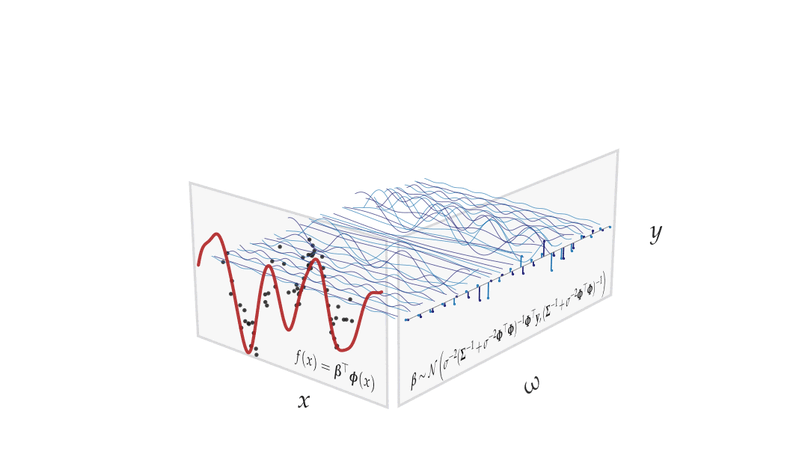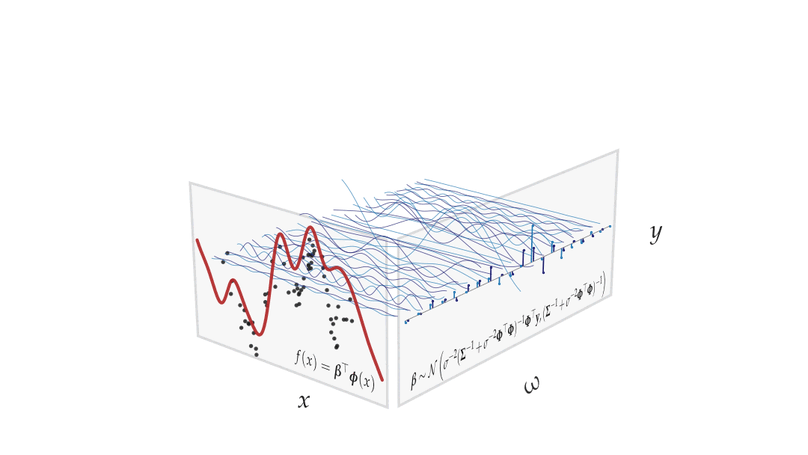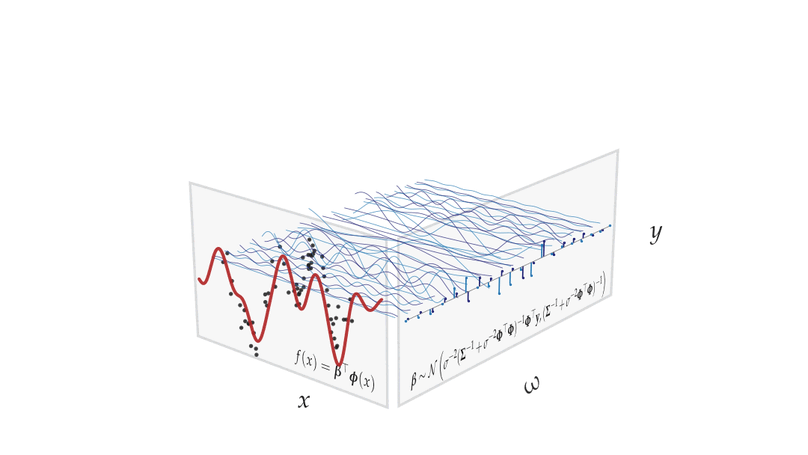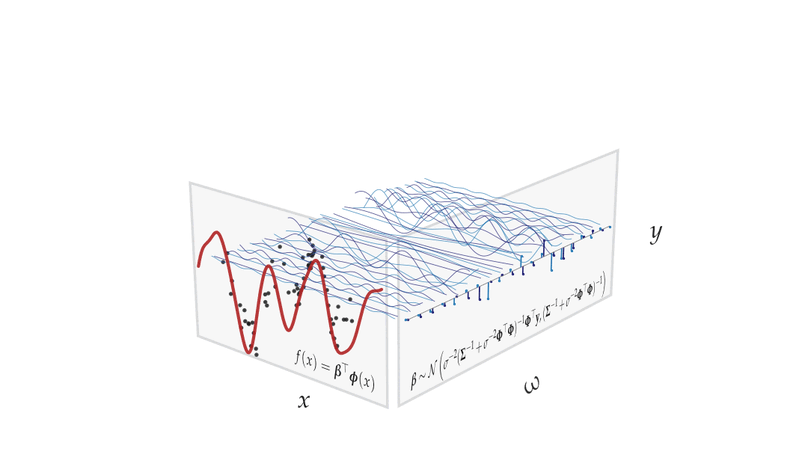

Teaching
Courses
COMP9418: Advanced Topics in Statistical Machine Learning (UNSW Sydney)
This course has a primary focus on probabilistic machine learning methods, covering the topics of exact and approximate inference in directed and undirected probabilistic graphical models – continuous latent variable models, structured prediction models, and non-parametric models based on Gaussian processes.
This course emphasized maintaining a good balance between theory and practice. As the teaching assistant (TA) for this course, my primary responsibility was to create lab exercises that aid students in gaining hands-on experience with these methods, specifically applying them to real-world data using the most current tools and libraries. The labs were Python-based, and relied heavily on the Python scientific computing and data analysis stack (NumPy, SciPy, Matplotlib, Seaborn, Pandas, IPython/Jupyter notebooks), and the popular machine learning libraries scikit-learn and TensorFlow.
Students were given the chance to experiment with a broad range of methods on various problems, such as Markov chain Monte Carlo (MCMC) for Bayesian logistic regression, probabilistic PCA (PPCA), factor analysis (FA) and independent component analysis (ICA) for dimensionality reduction, hidden Markov models (HMMs) for speech recognition, conditional random fields (CRFs) for named-entity recognition, and Gaussian processes (GPs) for regression and classification.
Publications
PDF Cite Code Poster Slides Video Conference Proceeding Supplementary material
Topics
Contact
Get in touch
Leave me a message: