An Illustrated Guide to the Knowledge Gradient Acquisition Function
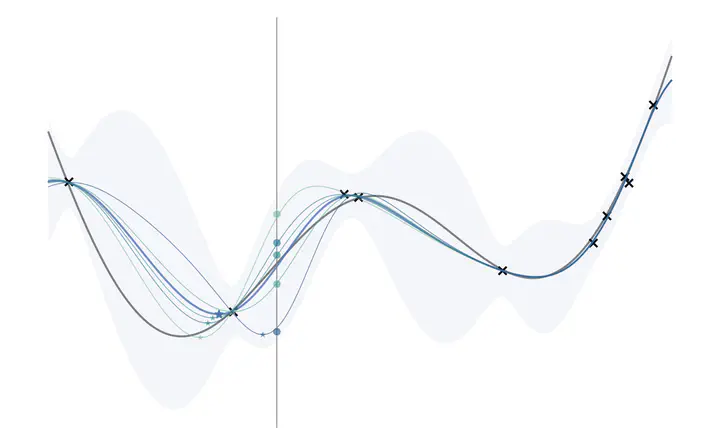
We provide a short guide to the knowledge-gradient (KG) acquisition function (Frazier et al., 2009)1 for Bayesian optimization (BO). Rather than being a self-contained tutorial, this posts is intended to serve as an illustrated compendium to the paper of Frazier et al., 20091 and the subsequent tutorial by Frazier, 20182, authored nearly a decade later.
This post assumes a basic level of familiarity with BO and Gaussian processes (GPs), to the extent provided by the literature survey of Shahriari et al., 20153, and the acclaimed textbook of Rasmussen and Williams, 2006, respectively.
Knowledge-gradient
First, we set-up the notation and terminology.
Let
Further, we make the following abbreviations
Monte Carlo estimation
Not surprisingly, the knowledge-gradient function is analytically intractable.
Therefore, in practice, we compute it using Monte Carlo estimation,
We refer to
We see that this approximation to the knowledge-gradient is simply the average
difference between the predictive minimum values based on simulation-augmented
data
This might take a moment to digest, as there are quite a number of moving parts to keep track of. To help visualize these parts, we provide an illustration of each of the steps required to compute KG on a simple one-dimensional synthetic problem.
One-dimensional example
As the running example throughout this post, we use a synthetic function
defined as
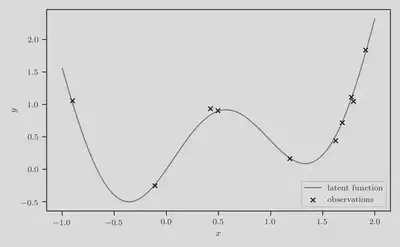
Using the observations
Posterior predictive distribution
The posterior predictive
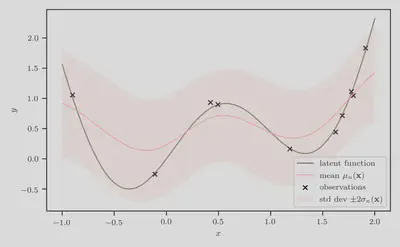
Clearly, this is a poor fit to the data and a uncalibrated estimation of the predictive uncertainly.
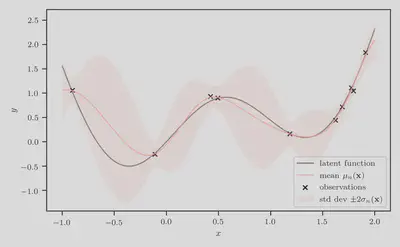
Step 1: Hyperparameter estimation
Therefore, first step is to optimize the hyperparameters of the GP regression model, i.e. the kernel lengthscale, amplitude, and the observation noise variance. We do this using type-II maximum likelihood estimation (MLE), or empirical Bayes.
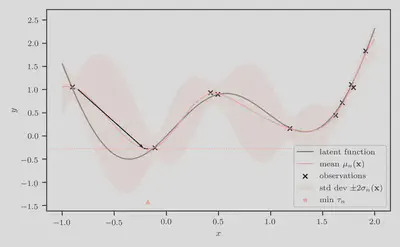
Step 2: Determine the predictive minimum
Next, we compute the predictive minimum
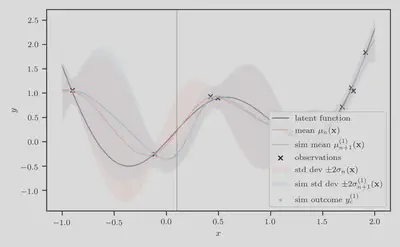
Step 3: Compute simulation-augmented predictive means
Suppose we are scoring the candidate location
In general, we denote the simulation-augmented predictive mean as
Here, the simulation-augmented dataset
Step 4: Compute simulation-augmented predictive minimums
Next, we compute the simulation-augmented predictive minimum
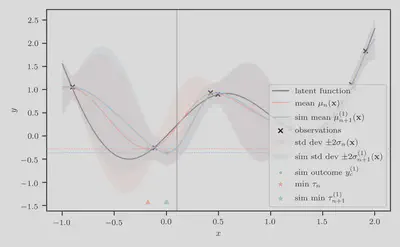
Taking the difference between the orange and blue horizontal dashed line will
give us an unbiased estimate of the knowledge-gradient.
However, this is likely to be a crude one, since it is based on just a single
MC sample.
To obtain a more accurate estimate, one needs to increase
Samples
Let us now consider
Accordingly, the simulation-augmented predictive means
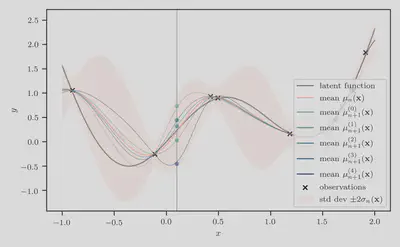
Next we compute the simulation-augmented predictive
minimum
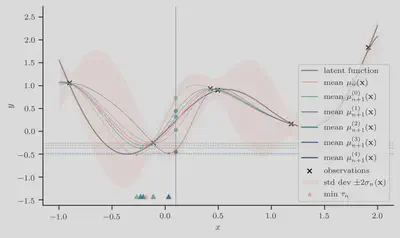
Finally, taking the average difference between the orange dashed line and every
other dashed line gives us the estimate of the knowledge gradient at
input
Links and Further Readings
- In this post, we only showed a (naïve) approach to calculating the KG at a given location. Suffice it to say, there is still quite a gap between this and being able to efficiently minimize KG within a sequential decision-making algorithm. For a guide on incorporating KG in a modular and fully-fledged framework for BO (namely BOTorch) see The One-shot Knowledge Gradient Acquisition Function
- Another introduction to KG: Expected Improvement vs. Knowledge Gradient
Cite as:
@article{tiao2021knowledge,
title = "{A}n {I}llustrated {G}uide to the {K}nowledge {G}radient {A}cquisition {F}unction",
author = "Tiao, Louis C",
journal = "tiao.io",
year = "2021",
url = "https://tiao.io/post/an-illustrated-guide-to-the-knowledge-gradient-acquisition-function/"
}
To receive updates on more posts like this, follow me on Twitter and GitHub!
Frazier, P., Powell, W., & Dayanik, S. (2009). The Knowledge-Gradient Policy for Correlated Normal Beliefs. INFORMS Journal on Computing, 21(4), 599-613. ↩︎ ↩︎
Frazier, P. I. (2018). A Tutorial on Bayesian Optimization. arXiv preprint arXiv:1807.02811. ↩︎
Shahriari, B., Swersky, K., Wang, Z., Adams, R. P., & De Freitas, N. (2015). Taking the Human Out of the Loop: A Review of Bayesian Optimization. Proceedings of the IEEE, 104(1), 148-175. ↩︎