Three eras of my dotfiles
We tour a chezmoi-templated dotfiles setup that bootstraps a fresh machine in one command — terminal, shell, prompt, multiplexer, multi-environment templating, and the developer …
We tour a chezmoi-templated dotfiles setup that bootstraps a fresh machine in one command — terminal, shell, prompt, multiplexer, multi-environment templating, and the developer …
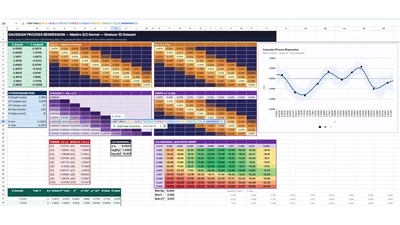
We implement a fully functional Gaussian Process regression pipeline — Cholesky decomposition, posterior predictions, and gradient-based hyperparameter optimization — in pure …
We give a short and practical guide to efficiently computing the Cholesky decomposition of matrices perturbed by low-rank updates.
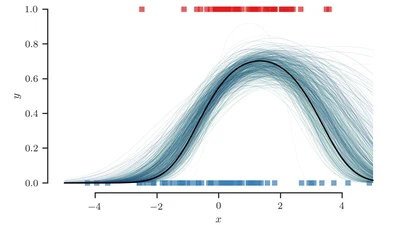
We use one weird trick — Pólya-Gamma augmentation — to make exact inference in Bayesian logistic regression tractable.

We give a short illustrated reference guide to the Knowledge Gradient acquisition function with an implementation from scratch in TensorFlow Probability.
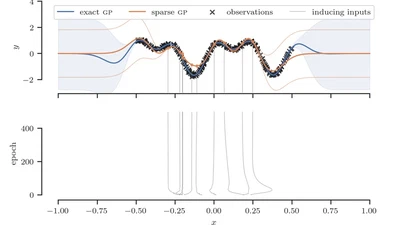
We summarize the notation, identities, and derivations underlying the sparse variational Gaussian process (SVGP) framework.
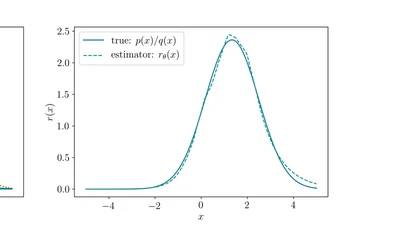
We show how to approximate the KL divergence (in fact, any f-divergence) between implicit distributions using density ratio estimation by probabilistic classification.
We illustrate how to build complicated probability distributions in a modular fashion using the Bijector API from TensorFlow Probability.
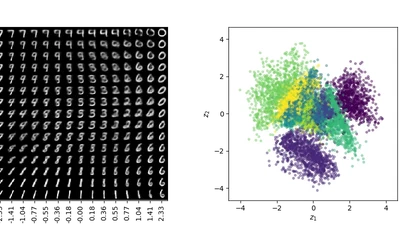
We give an in-depth practical guide to variational autoencoders from a probabilistic perspective.
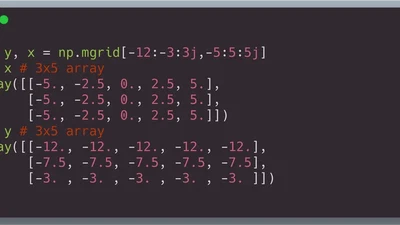
We compare NumPy's `mgrid` and `meshgrid` for building coordinate grids — what each does, why both exist, and how broadcasting often makes them optional.