Efficient Cholesky decomposition of low-rank updates
We give a short and practical guide to efficiently computing the Cholesky decomposition of matrices perturbed by low-rank updates.

We give a short and practical guide to efficiently computing the Cholesky decomposition of matrices perturbed by low-rank updates.
We extend BORE to the batch setting and establish theoretical convergence guarantees for parallel Bayesian optimization.
The 38th International Conference on Machine Learning (ICML 2021), virtual.
ELLIS AutoML Seminars (virtual).
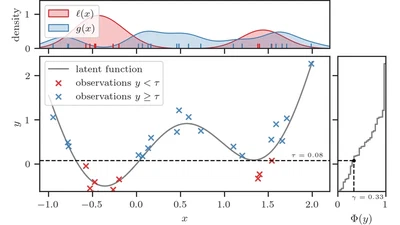
We reformulate the computation of the acquisition function in Bayesian optimization (BO) as a probabilistic classification problem, providing advantages in scalability, …
Our paper "BORE — Bayesian Optimization by Density-Ratio Estimation" was accepted to ICML 2021 as a Long Talk (top 3% of submissions).
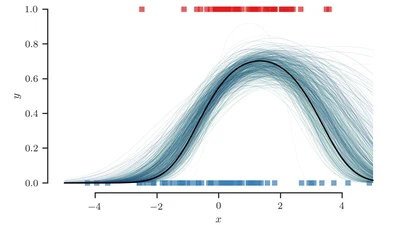
We use one weird trick — Pólya-Gamma augmentation — to make exact inference in Bayesian logistic regression tractable.

We give a short illustrated reference guide to the Knowledge Gradient acquisition function with an implementation from scratch in TensorFlow Probability.
NeurIPS 2020 4th Workshop on Meta-Learning (virtual).